

気候データで米の収量を予測!シエラレオネにおけるMLの実証研究
✨ 本論文の新規性
- シエラレオネの農業統計データのみで米収量を予測する初めてのML研究
- 気候データ(CHIRPS・NASA POWER)を組み込むことで予測精度が大幅向上
- データ漏洩を防ぐための厳格な検証手法を適用し、現実的な結果を示した
論文の主張: シエラレオネの米収量を予測するため、FAOSTATの農業統計と気候データ(CHIRPS・NASA POWER)を用いたMLモデルを検証。農業統計のみでは予測不能だが、気候データを加えることでRMSEが428kg/haから284kg/haへと改善。

今回の論文は、シエラレオネにおける米の収量を予測するための機械学習の試みで、データが限られている環境でも、気象データを組み合わせることで一定の精度で予測が可能であることが示されています。

なるほど、データがない中で気象データが役立つとは。特に「CHIRPS rainfall」と「NASA POWER temperature」を使った点が興味深いですね。
はい、その通りです。研究では、FAOSTATのデータだけでは予測が難しかったものの、気象データを加えることでモデルの精度が大幅に向上しました。特に、5月から6月の雨量が最も予測に強い影響を与えることが判明しています。
つまり、季節の雨量が収量の大きな指標になる、という点がポイントですね。それって、地域の農家が「今年の雨がいいかどうか」を判断するのにも役立ちそうです。
その通りです。また、この研究では、2018年の異常気象による収量の急落はモデルでは予測できなかったという点も指摘されています。これは、単なる気象の問題ではなく、制度的な側面も絡んでいる可能性を示唆しています。
制度の問題が気象の予測を上回るって、なかなか深いですね。データの限界って、やっぱり制度の構造にも左右されるんですね。
そうですね。また、地域レベルでの予測が可能になるためには、家庭レベルの微細データが必要です。今のところ、そのようなデータはまだ整っていません。
それって、現状の統計が集計されたレベルでしかないってことですね。現場レベルの情報が得られるようになるまでは、推測の精度は限界があるってことでしょうか。
はい。この研究の最大の貢献は、データが限られている環境でも、既存の自由な気象データを活用することで予測が可能であることを示した点です。また、オープンソースで公開されているため、他のデータ制約の多い国でも応用が可能です。
コストや導入の手間を考えると、既存のデータを活かすってのは、とても実用的ですよね。ただ、実際の農家にどうやって伝えるか、教育の仕組みも必要そうですね。
それは重要なポイントです。例えば、予測結果を農業協同組合や地方自治体が活用して、助成金や補助の対象を決める、といった形にも応用できるかもしれません。
補助金の配分に使われると、政策の透明性や公正性にも影響が出るかもしれませんね。
まさにその通りです。また、この研究では、モデルの精度を高めるためのデータの種類や、予測の信頼性を評価する方法が明確に示されています。
データの信頼性と、その評価の仕方って、農業に応用する際の大きな鍵ですね。技術の導入は、単なる精度だけでなく、現場での実行可能性も見極める必要があります。
背景と課題
シエラレオネは農業が主要な雇用源でありながら、データ駆動型の意思決定支援がほとんどない。特に米の収量予測は、現状の統計データだけでは不可能であることが判明。本研究では、FAOSTATの25年分のデータと衛星気候データを用いて、予測モデルの有効性を検証した。
手法・アプローチ
3つのENSEMBLEアルゴリズム(XGBoost、Gradient Boosting、Random Forest)を用い、農業統計データのみ、気候データのみ、および両者を組み合わせた3つのモデルを比較。データ漏洩を防ぐため、同じ年での情報は使用せず、2000〜2017年を学習、2018〜2024年をテストする「拡張ウィンドウ・ウォークフォワード評価」を採用。ベースラインには「前年をそのまま使う」手法を用いた。
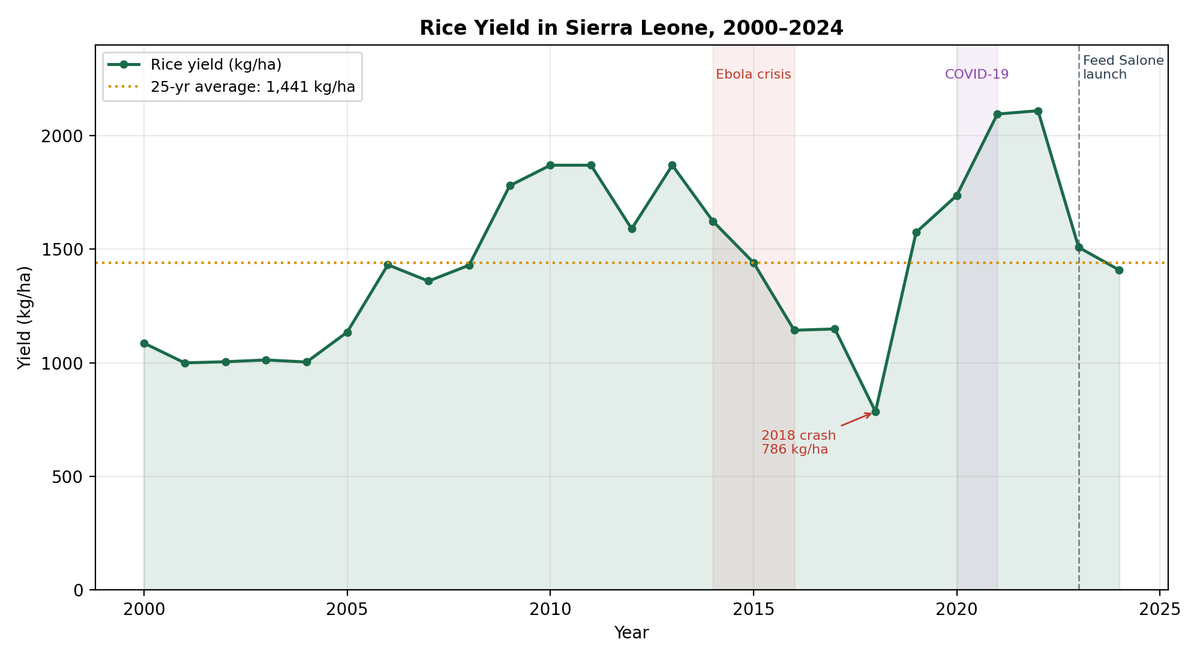
実験結果
農業統計のみでは、単純な前年予測(persistence)と比較して性能が悪化。一方、気候データを加えると、XGBoostモデルでRMSEが428kg/haから284kg/haへと改善。特に5〜6月の降雨量が最も予測力を持つことが判明。2018年の異常な低収量はモデルでは予測できなかったが、2020〜2022年の高収量は降雨量が少ないにもかかわらず予測可能だった。
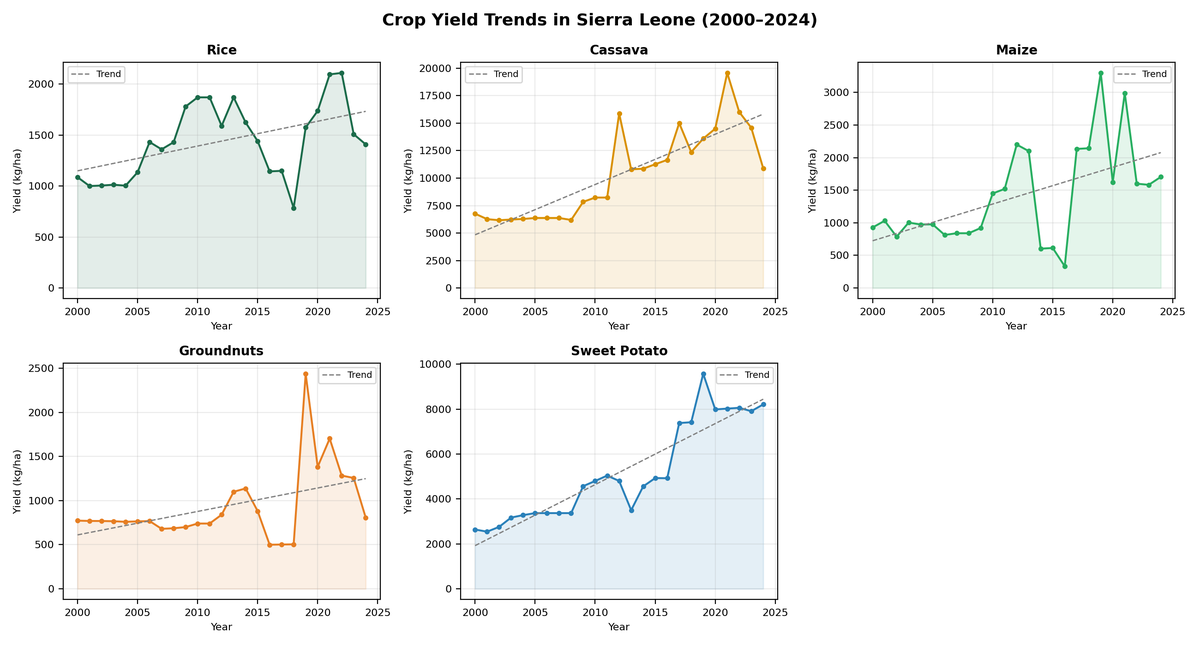
意義・応用可能性
シエラレオネのFeed Salone戦略の実施に必要なデータインフラ整備の指針となる。気候データを活用することで、予測精度が大幅に向上し、政策立案や農業支援の効率化が可能になる。特に、衛星データは無料で入手可能であり、他のデータ制約の厳しい国にも応用可能。
限界と今後の課題
本研究では、FAOSTATのデータに含まれる推定値が予測精度に影響を与える可能性がある。また、地域レベルでの予測精度向上には、家庭レベルのマイクロデータが必要。今後は、より詳細な地域・家庭レベルのデータを用いたモデル構築が求められる。
日本での適用可能性
日本でも気候データを活用した農業予測は進んでいるが、本研究のようにデータ制約が厳しい環境でのモデル構築は、地域の農業政策立案や災害時の対応に応用可能。特に、気候変動が影響する地域では、衛星データを用いた予測モデルの導入が有効。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: Can Machine Learning Forecast Rice Yields in Data-Constrained Settings? Satellite Climate Data, National Crop Statistics, and Lessons from Sierra Leone – 著者: Ibrahim Denis Fofanah – 発表日: 2026-06-11 – arXiv ID: 2606.13959v1 – カテゴリ: cs.LG