

動画の関係性理解を強化するQuestion-Aware Evidence Ledgers技術
✨ 本論文の新規性
- 動画QAタスクにおける関係性推論を強化するためのEvidence Ledgersを導入
- 質問の内容に応じたルーティングシステムにより、必要な証拠のみを抽出するアプローチ
- 保守的な回答更新ルールにより、モデルの過信を防ぎ、精度向上を実現
論文の主張: 動画における視覚的関係性推論を強化するため、質問の内容に応じたEvidence Ledgersを用いたテスト時推論パイプラインを提案。GPT-5.5をベースに、外部ツールによる証拠を統合し、92.95%の精度を達成。

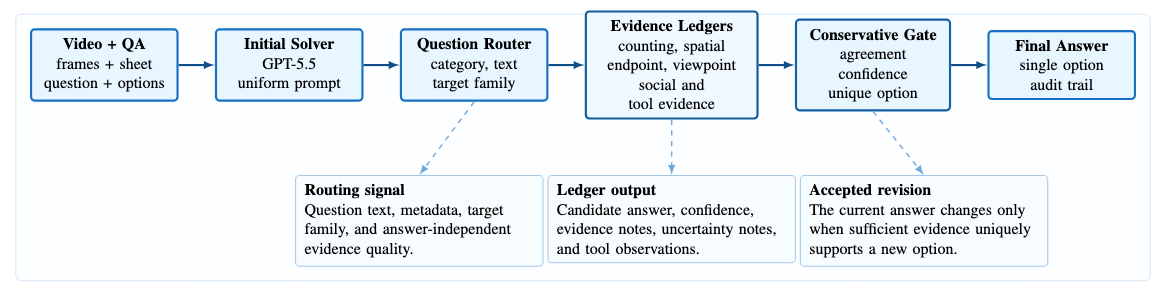
今回の論文は、動画における視覚的関係推論を高精度で行うためのテストタイムパイプラインを提案しています。特に、質問に応じた構造化された証拠を用いることで、モデルの推論を補強する手法を紹介しています。

なるほど、つまり質問の内容に応じて、必要な証拠を特定して集めていくってことですね。特に、数え上げや空間関係、視点などの推論を補助する仕組みがあるんですか?
はい、その通りです。例えば、「最初に何が起きたか」など時系列に関する質問には、開始時点のフレームを強調する「エンドポイントチェッカー」が働き、空間関係の質問には座標系や参照対象を明確にする「空間レジャー」が使われます。
へえ、それって結構複雑そうですね。最初の回答は一括で出すんでしょうか、それとも各質問ごとに処理するんですか?
初期の回答は全体のビデオと質問からGPT-5.5で一括で生成され、その後、ルーティングされたレジャーが、必要な情報を補完していきます。これは、モデルを再学習させずに、柔軟に推論できるという利点があります。
なるほど。つまり、初期モデルがベースで答えるけど、質問の種類に応じて補足情報を集めて精度を高めてるわけですね。でも、外部ツールが使われるのは限定的みたいだけど、どのくらいの精度が出たんですか?
この手法は、VRR-QAチャレンジというベンチマーク上でテストされ、全体の正解率が92.95%、マクロ平均で93.79%を達成しています。これだけ高い精度が出たのは、外部ツールの利用が「証拠の補助」として限定的に行われているからです。
すごい精度ですね。でも、コストや導入のハードルはどれくらいあるんでしょうか?運用するには、専門的な知識やツールの準備が必要そうだけど、実際の農業現場で導入するのは難しいかな?
これはテストタイムのパイプラインなので、学習は不要で、主に外部ツールの活用が前提です。ただ、外部ツールの導入には一定のコストが伴うため、実運用では規模や用途によって使い分けが必要です。
そうですね。それと、コストパフォーマンスの観点から、規模感が大切ですよね。この手法を導入するには、どのくらいの規模が必要になるんでしょうか?
現状では、大規模なビデオデータを扱う環境での評価が中心です。導入の際には、ビデオの処理コストや補助ツールの活用方法が重要になります。また、導入の初期投資は多少かかりますが、長期的には精度向上による改善が期待できます。
なるほど。補助金の影響も大きいですよね。この手法が、補助金前提のプロジェクトで導入される可能性も高いみたいですね。
そうですね。補助金の影響は大きいですが、技術的には補助金に依存せず、自社の業務に組み込めば活用可能である点も魅力です。ただ、導入の際には、運用体制やコストの見通しが必要でしょう。
それでは、実際の農業現場での活用は、技術的・コスト的なハードルが大きそうですね。でも、この手法は、動画解析の精度を高めるという意味では、今後のAI活用において重要な一歩かもしれません。
まさにその通りです。この手法は、動画分析における関係性推論を補強するための構造化されたアプローチであり、今後のAI導入の選択肢として非常に興味深いものです。
背景と課題
動画QAタスクにおいて、単一のフレームに依存するのではなく、空間的関係、イベント境界、ターゲットの同一性、会話文脈などの複雑な関係性を理解する必要がある。従来のモデルは、このような関係性を正確に推論できず、特に数え上げや空間的関係の推論において誤りが発生する。本研究では、これらの課題を解決するため、質問に応じたEvidence Ledgersを用いたテスト時推論手法を提案する。
手法・アプローチ
提案手法は、GPT-5.5を初期ソルバーとして使用し、質問の内容に応じて適切なEvidence Ledgersをルーティングする。各Ledgerは、ターゲット、操作、カウント単位、参照フレームなどを明示的に抽出する。外部ツール(検出器、深度推定、ASRなど)は証拠の提供のみに使用され、モデルの回答は保守的なゲートによって更新される。このアプローチにより、モデルの推論を明示的かつ信頼性の高い形に導く。
実験結果
提案手法はVRR-QAチャレンジのテストセットで、全体精度92.95%、マクロ精度93.79%を達成した。特に、数え上げや空間的関係、エンドポイントの推論において、従来手法より顕著な精度向上が確認された。保守的なゲートにより、誤った推論を防ぎ、信頼性の高い結果を導いている。
意義・応用可能性
本手法は、動画の視覚的関係性を理解するための強力なツールであり、農業分野における動画解析やロボット制御、作物の成長状況の推定などへの応用が期待できる。特に、複雑な空間的関係を必要とする農業ロボットの制御や、作物の生育状況を動画から推定するシステムに活用可能。
限界と今後の課題
本手法は、質問の内容に応じたルーティングとEvidence Ledgersの設計に依存しており、特定の質問カテゴリでは依然として誤りが生じる可能性がある。また、外部ツールの出力が不完全な場合、誤った推論を導くリスクがある。今後の課題としては、より高精度な外部ツールの統合と、ルーティングの精度向上が挙げられる。
日本での適用可能性
日本では、農業ロボットの導入が進んでいる中、動画を用いた作物の状況把握や、ロボットの動作制御に本手法が応用できる。例えば、作物の生育状況を動画から推定し、適切な施肥や病害虫の予防を行うシステムに活用可能。また、農業教育や研究においても、視覚的関係性の理解を支援するツールとしての可能性がある。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: Question-Aware Evidence Ledgers for Video Relational Reasoning – 著者: Yilin Ou, Mengshi Qi, Huadong Ma – 発表日: 2026-06-01 – arXiv ID: 2606.02506v1 – カテゴリ: cs.CV