

視覚言語モデルを活用した自動運転の3D車両ラベリング精度向上手法
📄 論文サマリー
著者:Steven Chen、Shivesh Khaitan、Nemanja Djuric
発表:arXiv(コンピュータビジョン)/2605.21747v1
公開日:2026年05月20日
✨ 本論文の新規性
- 視覚言語モデル(VLM)を用いて車両のメーカー・モデル・世代を推論し、3Dボックス寸法を推定する新しいアプローチを提案
- VLMによる推論結果をラベリングの初期値として活用することで、手動ラベリングの時間を短縮し品質を向上させる手法を実証
- 車両の修飾や損傷の有無を識別し、工場寸法とのズレを補正する機能を導入し、より正確なラベル生成を実現
論文の主張: 視覚言語モデル(VLM)を用いて車両のメーカー・モデル・世代を推論し、3Dボックス寸法を推定することで、自動運転のラベリング精度を向上させる手法を提案。

今回の論文は、視覚言語モデル(VLM)を活用して自動運転における3Dラベリングを改善するもので、特に車両のメーカー・モデルを推論することで、より精度の高いバウンディングボックスを生成する手法を提案しています

なるほど、つまり画像から車のメーカーとモデルを推定して、その寸法をもとに3Dボックスを生成する、ということですね
はい、その通りです。この方法では、まずVLMに車の画像を入力し、メーカー・モデル・世代を推論させ、それらの情報をもとに工場での実寸を出力します。これにより、手作業でのラベリングの初期値としてより正確な情報を提供できるとされています
データの精度を高めるという観点から、非常に興味深いですね。この手法、どのくらいの精度で推論できるんでしょうか
論文では、複数のVLMを比較した結果、特定のプロンプト設計により精度が向上することが示されています。また、特に遮蔽された状況下でも、初期のLiDARによるラベルよりも精度が上がることが確認されています
それはすごいですね。遮蔽状態での精度向上って、実際の運転環境では結構重要そうじゃないですか
はい、まさにその通りです。特に都市部や混雑した道路では、遮蔽が頻繁に起こるため、自動的に高品質な初期ラベルを生成できるのは大きな利点です
それって、ラベリングの時間短縮にもつながるんでしょうか
はい、実験結果では、手作業のラベリング時間の削減が見られ、ラベルの品質も向上していると報告されています。これは、大規模なデータセットの構築において、コストと時間の面で大きなメリットとなる可能性があります
なるほど、コストと効率の面でメリットがあるってことですね。でも、VLMの精度って、データの質に左右されるんでしょうか
その通りです。論文でも、プロンプトの工夫やVLMの選択によって結果が大きく変わるということが示されており、データセットの多様性や、モデルのトレーニング状況が重要な要素となっています
それは、導入の際の準備が必要そうですね。実際の運用で、どのくらいの規模感で導入できるんでしょうか
論文では、公開データと独自データの両方で評価が行われており、汎用性が示されているとされています。ただし、実運用に際しては、既存のラベリングフローとの統合や、精度の維持など、いくつかの課題が残っています
そうですね、導入の際には、既存のフローとの融合も大事そうですね。この技術、他にも応用できる場面はありますか
このアプローチは、主に自動運転のラベリングに焦点を当てていますが、将来的には、他の視覚認識タスクにも応用できる可能性があります。例えば、交通監視や車両追跡など、車両の属性推論が重要な分野では、応用が広がりそうです
そういった応用が広がるって、とても面白いですね。ただ、導入には初期投資や運用コストも考慮が必要そうですね
はい、確かにその通りです。この技術の導入には、VLMの利用コストや、ラベリングフローの再設計など、さまざまなコストが伴います。しかし、長期的には効率性の向上が期待できるため、導入の判断はプロジェクトごとの規模や目的によって異なると考えられます
つまり、メリットと課題のバランスを取って、実際の現場に合わせて導入する必要があるってことですね
はい、まさにその通りです。この技術は、一見して単純そうに見えますが、実際の運用では多くの要素を考慮する必要があります。今後の展開についても、技術の進化とともに、実用性が高まる可能性があります
では、今日はこの辺で。興味のある方は、元動画もぜひご確認ください
背景と課題
自動運転技術の進展に伴い、高品質な3Dラベルデータの必要性が増大している。従来は手動ラベリングが主流だったが、センサデータの多様性と複雑さにより、効率性と精度の両立が困難である。特に、遮蔽状態や車両の外観変更などによる誤判定が問題視されている。
手法・アプローチ
本研究では、視覚言語モデル(VLM)を用いて車両のメーカー・モデル・世代を推論し、その結果をもとに工場寸法を推定する手法を提案。VLMは画像入力から車両の形状・構成を推論し、寸法情報をJSON形式で出力。遮蔽状態や修飾の有無も考慮し、より正確な初期ラベルを生成する。
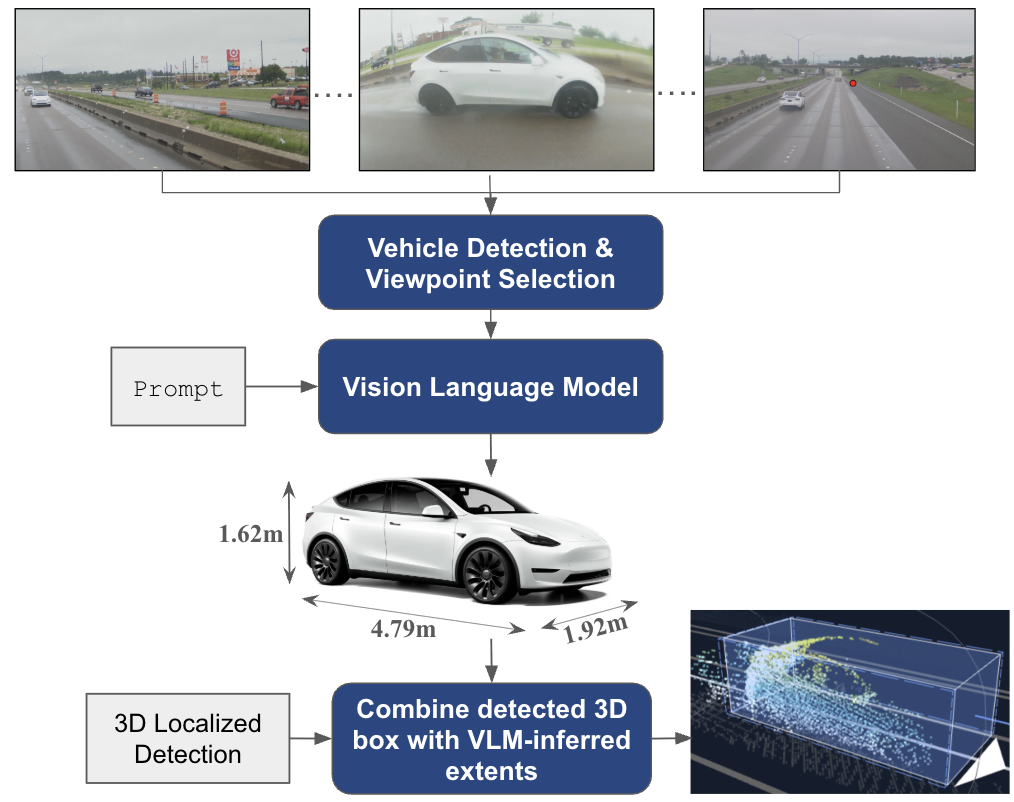
実験結果
内部データとWaymo Open Datasetを用いた評価で、Gemini Pro 2.5モデルが最も高い精度を示した。長さの絶対誤差は0.259メートル、幅は0.077メートル、高さは0.075メートルを達成。IoUは0.8831で、従来手法と比較して大幅な改善が確認された。

意義・応用可能性
本手法は、自動運転のデータ準備プロセスを効率化し、ラベリングの品質を向上させる可能性を示した。特に、遮蔽や外観変更が多発する都市部の運転環境において、高精度な初期ラベル生成が期待できる。
限界と今後の課題
本手法は、VLMの推論精度に依存しており、遮蔽が極端な状況では誤推論が発生する可能性がある。また、VLMの出力形式に依存するため、汎用性の向上が今後の課題である。
日本での適用可能性
日本では都市部の交通混雑や遮蔽が多いため、本手法の導入が特に有効。特に、車両の外観変更が見られる地域では、修飾情報の識別機能が重要視される。また、農業用自動運転車両のラベリングにも応用が期待できる。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: Improving 3D Labeling in Self-Driving by Inferring Vehicle Information using Vision Language Models – 著者: Steven Chen, Shivesh Khaitan, Nemanja Djuric – 発表日: 2026-05-20 – arXiv ID: 2605.21747v1 – カテゴリ: cs.CV