

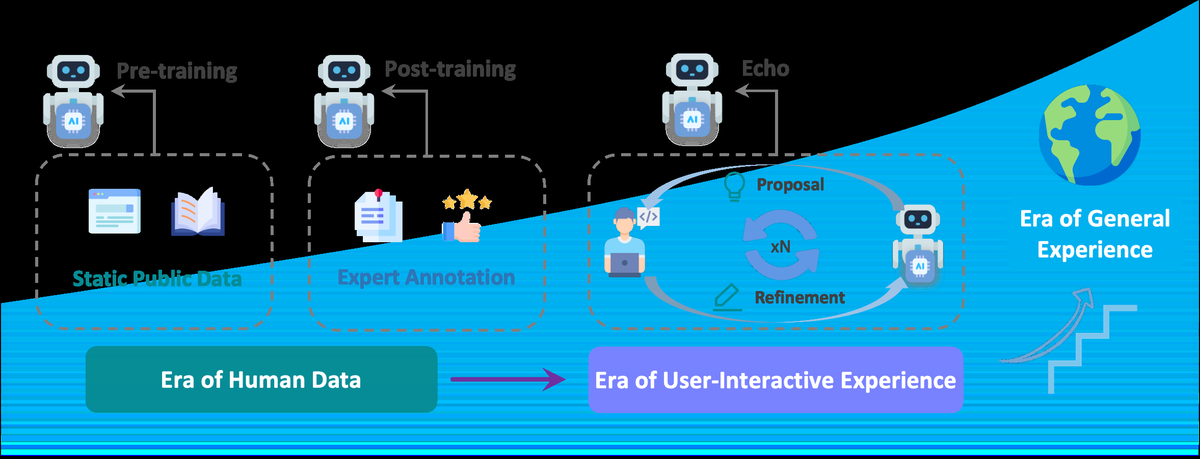
AIエージェントの実世界学習を可能にするEchoフレームワーク
✨ 本論文の新規性
- ユーザーフィードバックを活用したエージェントの継続的学習フレームワークを提案
- コード補完環境での実証実験により、静的データベースによる性能上限を突破
- エージェントの生成結果とユーザ修正の差分から高品質な学習信号を抽出する手法を導入
論文の主張: Echoは、AIエージェントが実世界でのユーザ修正を活用して学習する仕組みを提供。コード補完タスクにおいて、静的データによる性能上限を突破し、受容率を10%向上させた。

今回の論文は、『Echo: Learning from Experience Data via User-Driven Refinement』というタイトルで、AIエージェントが実際の環境との相互作用から学ぶ仕組みを扱っています。

なるほど、つまりユーザーのフィードバックを活かしてAIを改善する、ということですね?
はい、その通りです。従来は人間のデータをもとに学習していたのですが、それが限界があるとされており、この論文ではエージェントが実際に環境とやり取りしながら得た経験データを活かすアプローチを提案しています。
ユーザーが直接修正するって、つまり人間の判断が入るってことですか?
はい。ユーザーがエージェントの提案をもとに、最終的に正解に近づけるような修正を加えることで、その修正の流れから学習信号を抽出するという仕組みです。
それって、コストがかかるんでしょうか?
データ収集のコストは低いですが、この修正のプロセス自体は人間の手を必要とするため、コストの要素はあります。ただし、自動化できる部分もあるとされています。
実際の導入は、どのくらいの規模感で考えられているんですか?
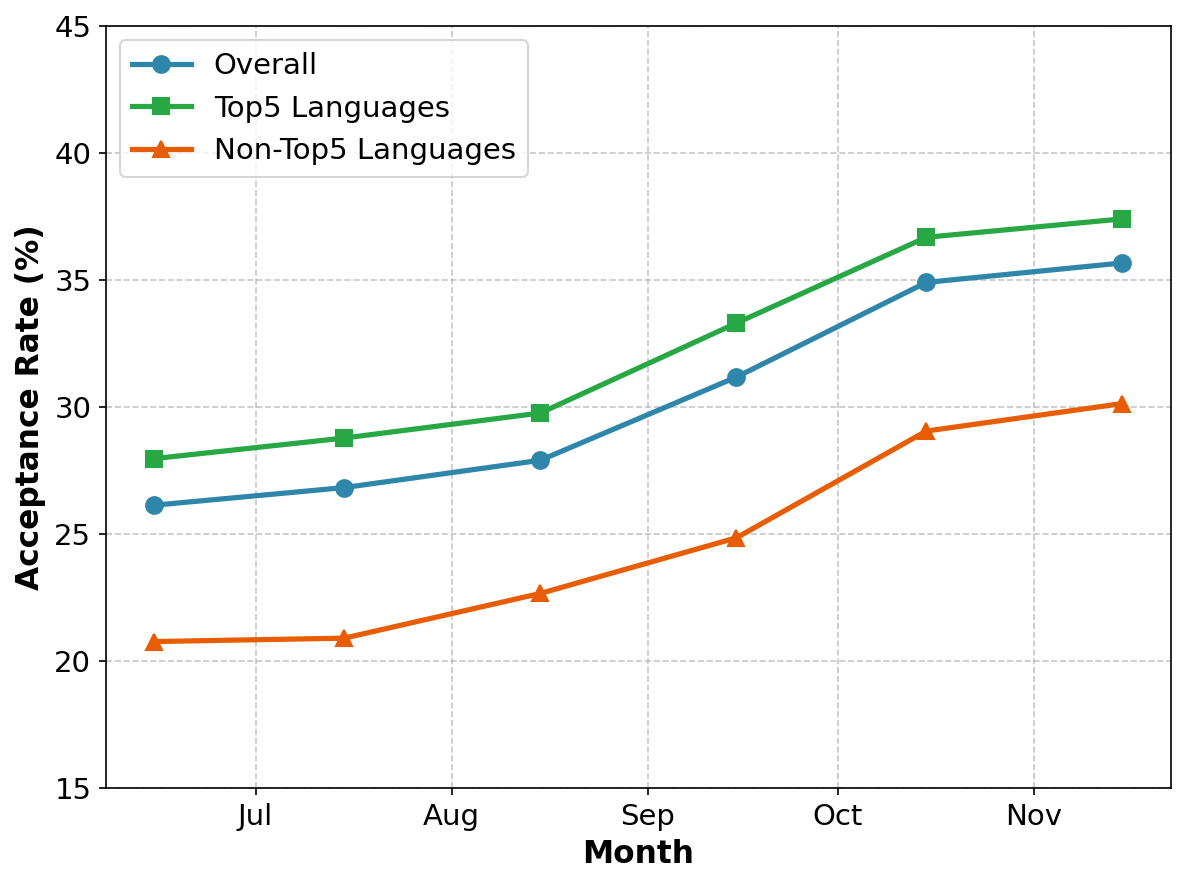
研究では、コード補完の環境で検証されており、acceptance rateが25.7%から35.7%に上がったと報告されています。これは、実際の運用においてかなり大きな改善です。
それって、コード補完の現場って、規模感の大きな企業とかじゃないと難しいんでしょうか?
企業規模によっては、ユーザーのフィードバックを体系的に集める環境が整っている場合もあります。ただ、中規模企業では導入のハードルが高い可能性もありますね。
補助金の有無は関係してくるんでしょうか?
それは関係するかもしれません。特に、AIを導入するにあたっての初期投資は大きいですが、長期的には効率の向上が見込めます。補助金の支援があれば、導入しやすくなる部分もありますね。
今後の展開としては、この仕組みが他の分野にも応用できるんでしょうか?
このアプローチは、環境との相互作用を通じて知識を習得するという汎用的な枠組みなので、教育や医療、ロボット工学など他の分野にも応用が期待できます。
背景と課題
従来のAIエージェント学習は、静的な人間データに依存しており、そのスケーラビリティや知識の限界が問題視されている。特に、高品質な人間データは限られているため、エージェントの性能向上が困難になる。本研究では、エージェントと環境の相互作用から得られる「経験データ」を活用し、継続的に学習する手法を提案する。
Echoフレームワークの構成
Echoは、3つの段階からなるフレームワークである。まず「経験取得」で、エージェントと環境の相互作用から生じるノイズの多いログを収集する。次に「知識抽出」では、ユーザの修正行動を活用し、エージェントの初期提案と最終的な正解を比較して学習信号を抽出する。最後に「モデル最適化」では、抽出された信号を用いてエージェントの生成分布を調整し、より正確な出力を学習させる。
実験と結果
コード補完タスクにおいて、Echoを導入した結果、静的ベースラインと比較して受容率が25.7%から35.7%へと10%向上した。また、外部ユーザーへの一般化能力も確認され、データ量の増加に伴って性能が継続的に向上する傾向が見られた。これは、エージェントが実世界の経験から学習し続けることが可能であることを示している。
意義と応用可能性
Echoは、AIエージェントが実世界のフィードバックを活かして学習できるという可能性を示した。特に、開発者や農業現場でのAI補助ツールにおいて、ユーザの修正を学習に活かすことで、より適切な出力を生成できる可能性がある。これにより、AIの実用性と信頼性が向上する。
限界と今後の課題
本手法は、ユーザの修正行動を正確に抽出する必要があるため、修正の明確性や一貫性に依存する。また、経験データの品質が学習効果に大きく影響するため、データの前処理やフィルタリングの精度が重要である。今後は、より自動化されたフィードバック抽出技術の開発や、多様な環境での適用性の検証が必要である。
日本での適用可能性
日本農業現場においても、AI補助ツールがユーザのフィードバックを学習に活かすことで、より適切な農業作業支援が可能になる。例えば、農業ロボットの作業指示や作物管理の提案において、実際の作業結果と比較して修正を学習することで、より精度の高い意思決定が可能になる。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: Echo: Learning from Experience Data via User-Driven Refinement – 著者: Hande Dong, Xiaoyun Liang, Jiarui Yu, Jiayi Lin, Changqing Ai, Feng Liu, Wenjun Zhang, Rongbi Wei, Chaofan Zhu, Linjie Che, Feng Wu, Xin Shen, Dexu Kong, Xiaotian Wang, Qiuyuan Chen, Bingxu An, Yueting Lei, Qiang Lin – 発表日: 2026-05-21 – arXiv ID: 2605.21984v1 – カテゴリ: cs.AI