

SEDiTで字幕消去、マスク不要な1ステップ動画編集技術
✨ 本論文の新規性
- マスク生成を不要とするSEDiTの1段階動画字幕消去手法を提案。従来手法の2段階処理に代わるアプローチ。
- Diffusion Transformerを活用し、字幕領域の局所的分布変化に適応した1ステップ推論を理論的根拠付きで実現。
- 高解像度1440p動画を無限長に対応するチャンク処理方式を導入し、実用性を向上。
論文の主張: 動画字幕の消去を、マスク不要で1ステップで行うSEDiTを提案。Diffusion Transformerを用いた一貫した推論により、高品質かつ効率的な字幕除去が可能に。

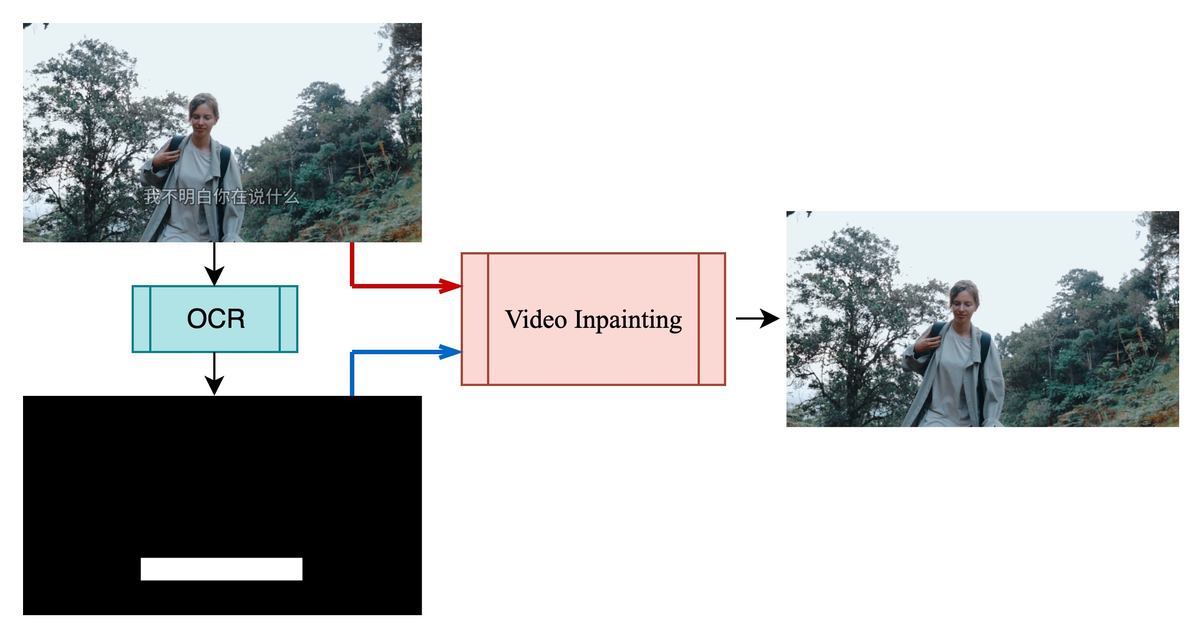
この論文は、動画の字幕を消去するための新しい手法を提案しています。従来の方法では、マスクを事前に生成する必要がありましたが、SEDiTはそのプロセスを一ステップで行えるようにしています。

なるほど、マスク生成が不要になるというのは、作業効率面でも大きな利点そうですね。特に字幕の複雑な表現や透過性があると、マスクが正確に取れないケースもあるんでしょうし。
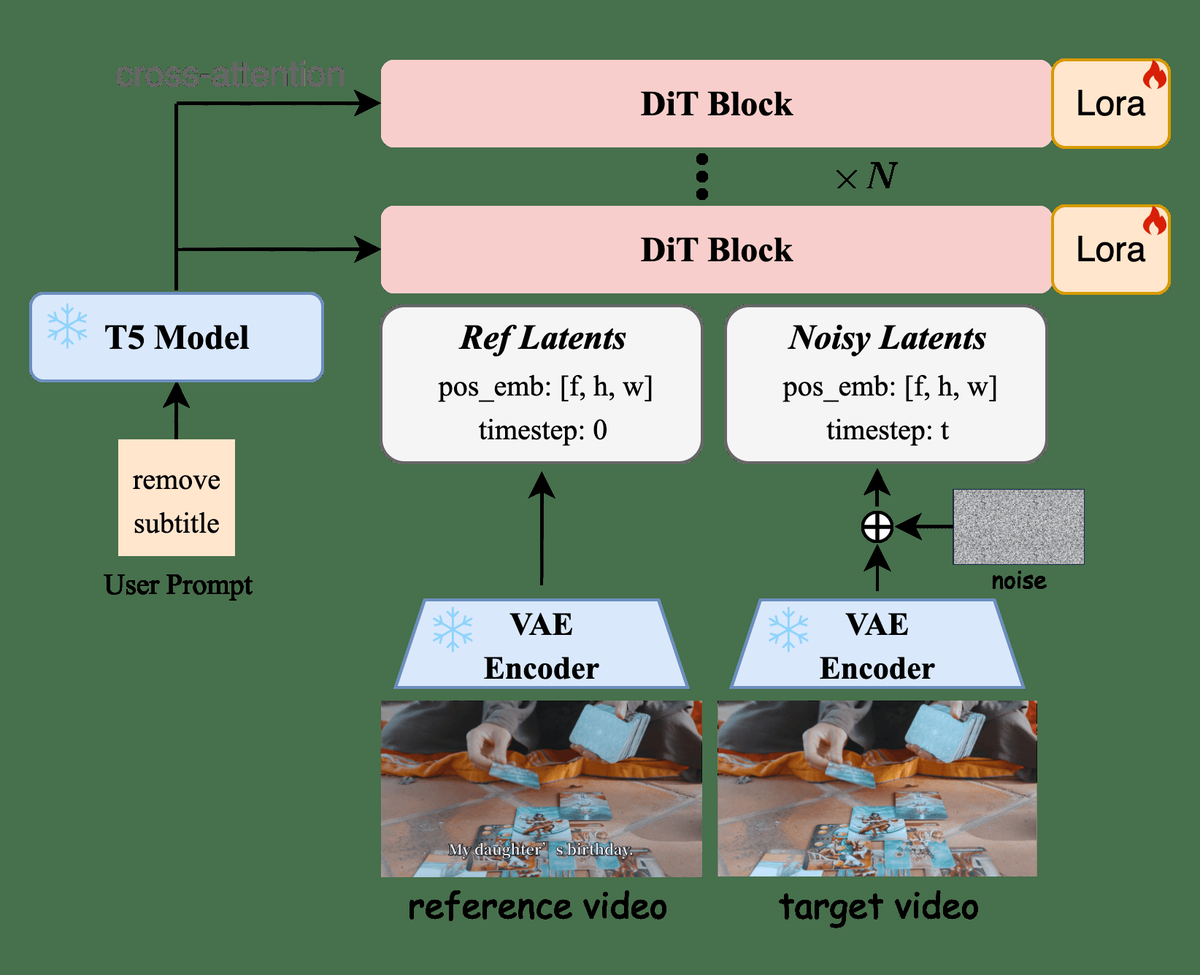
その通りです。研究では、字幕を消去するというタスクが局所的 editing であるため、一ステップで処理できる可能性を示しています。また、条件付き輸送の理論的根拠も示されており、これにより一歩前進したと評価されています。
あ、それってつまり、字幕が動くような場面でも、前のフレームを参照して滑らかに処理できるってことですか?
はい、その通りです。動画の長期的な時間的一貫性を保つために、特定のフレームを参照する方式を取り入れています。これは、画像処理の手法とは異なり、動画の流れを考慮した設計になっています。
そういえば、動画の字幕を消すって、映像編集ソフトでも昔からある機能じゃないですか。これって、それとは違う分野の技術ってことですか?
その通りです。従来の技術は、手動でのマスク作成や、特定のオブジェクトを特定する手法が多かったですが、SEDiTはマスクなしで一括処理が可能であり、より自動化された方法です。
なるほど、それってつまり、既存のシステムに組み込むのが難しそうですね。技術的なハードルが高く、導入に時間がかかるかもしれません。
その通りです。技術的な整合性を保つために、モデル構造の変更は最小限に抑えられており、実装のしやすさも考慮されていますが、トレーニングや推論コストは依然として高めです。
コスト面、見通しが立たないですね。補助金前提のビジネスモデルじゃないと、実運用は難しいかもしれませんね。
それは重要なポイントです。この論文では、データ合成のパイプラインを整備し、実用的なデータを用意することで精度を向上させています。ただ、これも訓練のコストが伴うため、規模感によっては導入が難しいかもしれません。
実際の動画処理の実装コストも含めて、コストとROIを見極める必要がありそうです。
はい。また、動画の長さや解像度によって処理の粒度を調整できるようにしているため、実運用における柔軟性は高いです。ただ、それだけの精度を保つには、高度な技術的な知識とリソースが必要になります。
技術的には面白いけど、実際の農業現場にどう応用できるかは難しいかもしれませんね。でも、こういった研究が進んでいるのは、今後の可能性を広げる上で重要な一歩です。
まさにその通りです。技術の進歩は、常に実務と接する中で、さらに価値が生まれるものです。今回の手法は、動画処理分野において新たな可能性を示していると言えるでしょう。
背景と課題
従来の動画編集技術では、字幕除去に際しては事前マスク生成が必要であり、精度に依存するという課題があった。特に、透明性やグラデーションを持つ字幕はセグメンテーションが困難で、品質の劣化が生じる。本研究では、マスク不要な1ステップ推論を実現し、字幕の局所的変化に適応した高品質な除去を目的とする。
手法・アプローチ
SEDiTは、LTX-VideoをベースとしたDiffusion Transformerを用いたマスクフリー字幕除去手法。条件付き動画潜在空間をノイズ潜在空間と連結し、一貫した推論を行う。字幕領域の局所性を活かし、1ステップで字幕除去を実現。また、長時間動画に対応するためのチャンク処理方式を採用。
実験結果
VSR-Bench-400データセットでの評価において、SEDiTはMinimax-Removerを上回るPSNR(31.59)、SSIM(0.8805)、LPIPS(0.0982)を達成。推論時間は1ステップで4秒と、従来手法の数分に比べて大幅に短縮。特に、字幕の境界が複雑なケースでも高い再構成品質を示した。
意義・応用可能性
動画編集における字幕除去の自動化を可能にし、特にテレビドラマやアニメの字幕除去に応用が期待できる。農業映像の字幕除去など、視覚的干渉を排除する必要がある場面にも適用可能。効率的な推論により、リアルタイム処理が可能になる。
限界と今後の課題
本手法は字幕領域の局所性に依存しており、複雑な背景や動体の影響で誤認識が生じる可能性がある。また、入力動画の品質に依存するため、ノイズが多い動画では再構成品質が低下する。今後の課題として、より広範な字幕スタイルへの対応と、リアルタイム処理のさらなる高速化が挙げられる。
日本での適用可能性
日本では、テレビ番組や動画配信での字幕除去が頻繁に求められる。本手法は、字幕の種類や配置に依存せず、自動で処理できるため、NHKや各放送局の編集作業の効率化に貢献できる。また、農業映像の字幕除去など、視覚的干渉を排除する用途にも応用が期待される。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: SEDiT: Mask-Free Video Subtitle Erasure via One-step Diffusion Transformer – 著者: Zheng Hui, Yunlong Bai – 発表日: 2026-05-14 – arXiv ID: 2605.14894v1 – カテゴリ: cs.CV