

言語モデルの推論プロセスを前向きに評価するCROPの導入
📄 論文サマリー
著者:Matt Y. Cheung、Ashok Veeraraghavan、Hanjie Chen、Guha Balakrishnan
発表:arXiv(人工知能)/2605.30085v1
公開日:2026年05月28日
✨ 本論文の新規性
- 言語モデルの推論トレースにおける中間ステップの信頼性を統計的保証付きで評価する手法を提案
- 従来の最終出力のみの評価ではなく、連続的な推論の前半部分を安全に利用可能にする手法を導入
- 任意のステップレベルのリスクプロキシを用い、適合性を保証する前向きな認証手法を実装
論文の主張: 言語モデルの推論トレースにおいて、途中でエラーが発生する前までの有効な推論を統計的に保証する手法CROPを提案。これにより、推論の安全性と再利用性のバランスを改善。

今回の論文は『Conformal Certification of Reasoning Trace Prefixes』で、言語モデルの推論過程を逐次的に評価し、安全に利用できる部分を切り出す方法を提案しています。

なるほど、つまり途中のステップまで信頼できるかどうかを判断するんでしょうか?
はい、その通りです。従来の方法では、最終的な答えか、全体の出力を.certify(証明)するものが多く、中間ステップの評価は難しいのが課題でした。この手法は、各ステップのリスクを評価し、その中で最も長く信頼できる連続した前半部分だけを抽出するんです。
あ、そういえば、推論途中でミスが出てきたら、それ以前のステップは信用できるってことですね?
まさにその通り。CROP(Conformal Reasoning Output Prefixes)という手法は、各ステップごとのリスクスコアを用いて、どの時点までを安全に信頼できるかを統計的に制御しています。
それは効率的ですね。それって、例えば、途中で誤った計算が入ったら、それ以前の正しい計算を活かせるってことでしょうか?
そうなんです。推論過程の中で、最初は正しいステップが多いですが、途中で誤りが発生すると、それ以降は信用できなくなります。CROPはそれを区別し、有効な部分だけを残して、後半を再検討対象として切り離すんです。
データベースの評価方法も変わってくるんでしょうか?
はい、従来のAUROCのような指標では、prefixの利用価値を正確に測るのが難しいとされています。CROPは、実際にどの長さのprefixが信頼できるかを示すことで、評価の指標も見直すべきです。
そうですね、評価方法が変われば、それに合わせて技術の改善も進むんでしょう。
その通りです。また、実験結果では、CROPは誤って切り捨てたり、信用できるのに切り捨てたりするバランスを取ることができ、特に後段の修正プロセスに有利な結果を示しています。
なるほど。技術的側面だけでなく、運用面でのメリットも大きいですね。
そうですね。この手法は、既存の推論評価器に依存せず、様々なリスク代理指標に対応できる点も特徴です。つまり、柔軟な導入が可能です。
実際、導入するには、どのくらいのコストがかかるんでしょうか?
技術的には、既存のモデルを活用するだけなので、導入コストは比較的低いです。ただし、評価用のデータセットや調整の手間は必要です。
それは良いですね。導入のハードルが低いってのは、実用性の面でも有利そうですね。
まさにその通り。この手法は、推論のプロセスをより信頼できるものにし、最終的な結果の精度を向上させる可能性を秘めています。
背景と課題
現代の言語モデル(LM)は複雑な問題を解くために推論トレース(chain-of-thought)を生成する。しかし、最終的な出力が誤っても、初期の推論は多くの場合正しい。従来の不確実性評価(UQ)手法は全体の出力や最終ラベルのみを評価し、途中の推論の信頼性を保証できない。この課題に対処するため、CROP(Conformal Reasoning Output Prefixes)を導入。これは、推論の前半部分を安全に利用できるようにする適合性評価手法であり、エラーの発生位置を前向きに評価する。
手法・アプローチ
CROPは、任意のステップレベルのリスクプロキシ(例:PRM、尤度、ヒドゥンステート統計)を用い、推論トレースの各ステップにリスクを割り当て、その閾値を設定して、エラーが含まれない最大の連続部分を返す。この手法は適合性予測(Conformal Prediction)を応用し、推論インスタンスの交換可能性(exchangeability)の仮定の下で、 marginal probability が指定されたリスクレベル以下になるように保証する。CROPは、推論の途中でエラーが発生する前までの部分を安全に抽出し、残りの部分を後続処理に渡す。
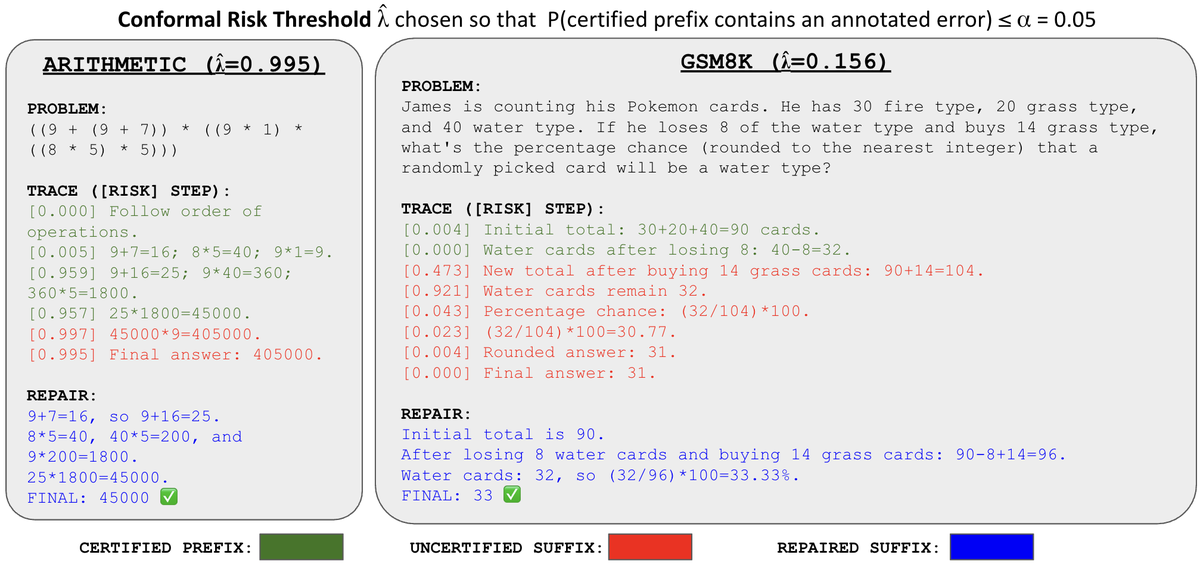
実験結果
CROPは6つの推論データセット(Arithmetic、GSM8K、ProcessBench、Math-Shepherd、PRMBench、PRM800K)で評価された。標準的なAUROCなどの指標では、推論の前半部分の有用性を正確に評価できないことが示された。一方、CROPは、推論の前半部分をより正確に抽出し、全体の推論の安全性と再利用性を向上させた。特に、ArithmeticとGSM8Kでは、CROPが提供する前半部分の長さが、人手でのアノテーションに基づくクリーンな前半部分に近い結果を示した。また、CROPを用いた場合、後続の修復精度が従来手法と比較して改善された。
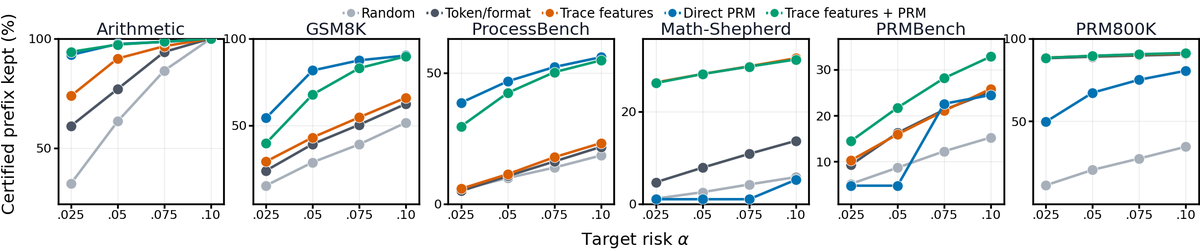
意義・応用可能性
CROPは、言語モデルの推論プロセスをより細かく評価し、安全かつ効率的に利用できるようにする。特に、農業分野においては、複雑な推論を含むAIシステムの信頼性を高める可能性がある。例えば、作物の病害診断や栽培計画の推論において、途中の推論を安全に利用し、最終的な判断に必要な情報を再利用することで、精度と効率の両面で向上が期待できる。
限界と今後の課題
CROPは推論トレースの前半部分を抽出するが、後半の修復方法については指定しない。また、リスクプロキシの品質に依存するため、弱いプロキシでは保守的になり、有用な推論を失う可能性がある。さらに、データの交換可能性(exchangeability)の仮定が満たされない場合、保証が成り立たない。今後の課題として、より強力なリスクプロキシの設計や、CROPと修復手法の統合が挙げられる。
日本での適用可能性
日本農業では、複雑な推論を伴う意思決定が増加しており、CROPの導入は推論の安全性と再利用性を高める可能性がある。例えば、病害診断や栽培計画の推論において、途中の推論を安全に利用することで、AIの判断を補助し、農業現場での意思決定の精度を向上させることができる。また、CROPは、推論の途中でエラーが発生する前までの部分を抽出するため、農業AIの信頼性向上に寄与する。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: Conformal Certification of Reasoning Trace Prefixes – 著者: Matt Y. Cheung, Ashok Veeraraghavan, Hanjie Chen, Guha Balakrishnan – 発表日: 2026-05-28 – arXiv ID: 2605.30085v1 – カテゴリ: cs.AI