

SAGEによる音楽ストリーミング fraud 検出の精度向上 — 訓練データの偏りを解消する手法
✨ 本論文の新規性
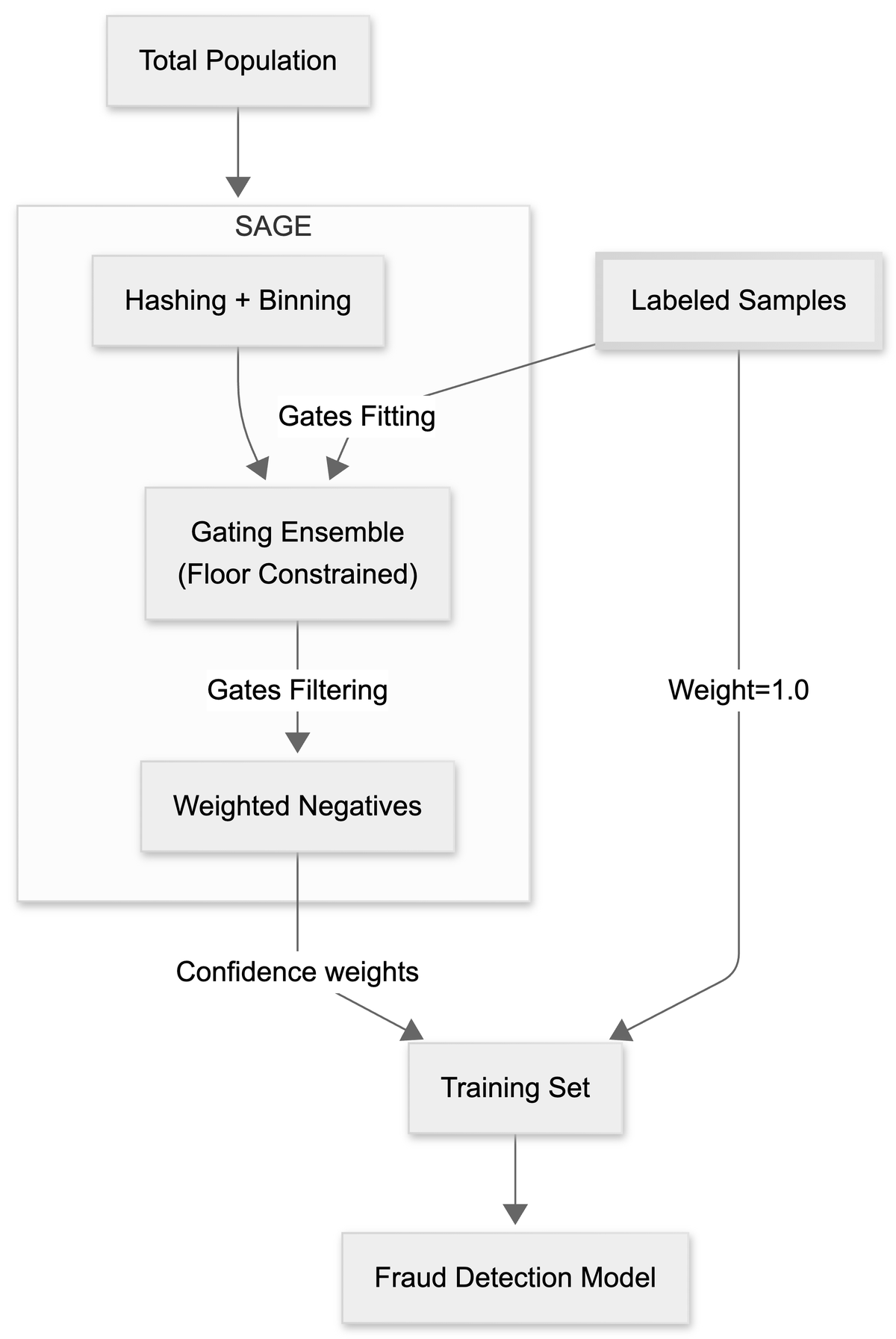
- Positve-Unlabeled学習におけるcounterfactual problemを解決するための、SimHashベースの層別サンプリング手法を提案
- 統計的ゲートを用いたconfidence filteringにより、信頼性の高いnegativeサンプルを効率的に抽出する自動ゲートENSEMBLEアーキテクチャを構築
- edge case(例:スーパーファン、睡眠音楽セッション)の代表的な行動パターンを捉えるため、floor-constrained samplingを導入
論文の主張: 音楽ストリーミングサービスにおけるfraud検出において、従来の手法では少数のfraudケースと大量のlegitimateな行動パターンを区別しきれなかった問題に対し、SAGEはSimHashと統計的ゲートを用いた自動的なnegativeサンプル抽出により精度を大幅に向上させた。

今回の論文は、音楽ストリーミングにおける詐欺検出を目的とした新しい手法SAGEについてです。特に、正例だけがラベル付けされたデータから、信頼性の高い非正例を効率的に抽出する方法を提案しています。

なるほど、PU学習の応用ですね。特に、詐欺と見なせるケースと、普通のユーザーの行動が似ているケースをどう区別するかがポイントなんでしょうか?
はい、その通りです。特に、スーパーファンや睡眠中に音楽を聴くようなエッジケースが詐欺のパターンと似ているという問題を解決するために、SimHashベースの層別サンプリングと統計的ゲートの組み合わせを採用しています。
あ、そうだったんですか。層別サンプリングって、データの偏りを補正するのに効果的ですよね。でも、実際の運用では計算リソースの問題は大丈夫なんでしょうか?
その点についても、floor-constrained samplingによって少数クラスの代表例を確保するように設計されており、極端な計算負荷を回避する工夫がされています。
なるほど、データのバランスを取る上でかなり工夫がされているんですか。これ、既存のシステムに組み込むのは難しいんでしょうか?
論文では、既存のfraud detectionシステムに統合可能な形で構成されており、特に計算コストやリアルタイム性に配慮した設計となっています。
それは良いですね。ただ、補助金や支援制度が前提のシステムだと、政策変更で大きく影響を受ける可能性もありますよね。
それはまさにその通りです。この研究は企業内部での導入を想定しており、外部的な支援が前提ではないため、実運用における柔軟性は高いですが、環境変化への対応も重要です。
そうですね、導入の際には環境の変化にも対応できるように準備が必要そうですね。
さらに、この手法はfraud detectionの分野にとどまらず、他の異常検知にも応用可能とのことです。例えば、金融分野やネットワークセキュリティなどでの活用が期待されています。
金融分野で活用されるなんて、面白いですね。データの性質が似ているので、適用範囲は広そうです。
はい、特に異常検知において、正例だけが得られるような状況では、このアプローチが有効な可能性が高いです。
データのバランスをどう取るか、という点はとても重要なテーマですね。この研究は、それに対する一つの解決策を示しているんでしょうか。
まさにその通りです。この研究では、PU学習における代表的な課題であるrepresentation biasを解決するための新しい枠組みを提供しています。
背景と課題
音楽ストリーミング業界は急速に成長しているが、fraud(詐欺)が深刻な問題となっている。特に、AIを用いたbotネットワークによるストリーム数の操作は、royalty paymentシステムを悪用する手段として問題視されている。従来のfraud detection手法は、legitimateな行動パターン(例:スーパーファン、睡眠音楽セッション)がfraudと似ていることから、誤検出が発生するという課題がある。この問題に対し、SAGEはPositive-Unlabeled学習を活用し、信頼性の高いnegativeサンプルを抽出することで、モデルの精度を向上させる。
手法・アプローチ
SAGEは、2つの主要なコンポーネントから構成される。1つ目はSimHashを用いた層別サンプリングで、customerの行動を分類し、少数のedge caseも適切にカバーする。2つ目は、統計的ゲート(Mahalanobis距離とk-NN密度推定)を用いたconfidence filteringで、negativeサンプルを抽出する。このゲートは、fraudと異なる行動を検出するために、globalな統計的特徴とlocalな密度を考慮する。複数のゲートを用いた投票方式により、precisionとrecallのバランスを調整可能である。
実験結果
SAGEは、Isolation Forestをベースラインとした場合、精度(Precision)で+81.9pp、再現率(Recall)で+87.2ppの向上を示した。特に、edge caseの検出精度が向上し、従来の手法では誤検出が多かった少数のcustomerセグメントのfraud検出性能が大幅に改善された。この結果は、SAGEがfraud detectionの課題に適応的であることを示している。
意義・応用可能性
SAGEは、音楽ストリーミング以外にも、金融fraud、spamフィルタリング、セキュリティ監視など、少数のpositiveサンプルと大量のunlabeledデータがある分野に応用可能である。特に、edge caseの検出精度が向上することで、誤検出を減らし、人間の介入を最小限に抑えることが期待できる。
限界と今後の課題
SAGEは、少数のfraudラベルを必要とするため、初期のラベル付けに依存する。また、threshold tuningには多くの手作業が必要であり、モデルの更新頻度が重要である。さらに、時間の経過に伴うfraudの変化(temporal drift)に対応するための拡張が必要である。
日本での適用可能性
日本における音楽ストリーミングサービス(例:Spotify、Apple Music、Amazon Music)においても、fraudの検出精度を向上させる可能性がある。特に、日本では音楽のジャンルや聴き方の多様性が高く、edge caseの検出精度が重要視される。SAGEの手法は、日本市場のcustomer行動の特徴に合わせて調整可能であり、今後の導入が期待される。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: SAGE: Scalable Automatic Gating Ensemble for Confident Negative Harvesting in Fraud Detection – 著者: Sudheer Tubati, Amit Goyal – 発表日: 2026-05-19 – arXiv ID: 2605.20157v1 – カテゴリ: cs.LG