

果物識別に革命をもたらすFruitEnsemble:言語モデルと視覚ensembleの融合
📄 論文サマリー
著者:Enhui Yu、Junhui Li、Ruitong Lu、Jialu Li、Youshan Zhang
発表:arXiv(コンピュータビジョン)/2605.20892v1
公開日:2026年05月20日
✨ 本論文の新規性
- 306カテゴリの果物を対象とした大規模データセットFruit-306を構築し、視覚と言語の融合を可能にした。
- 視覚ensembleとMLLMの動的融合手法を導入し、推論効率と精度のバランスを実現した。
- ハードサンプルに特化したjoint optimizationにより、特に稀少品種の識別精度を向上させた。
論文の主張: 視覚と言語を融合したFruitEnsembleは、306カテゴリの果物を高精度で識別し、リアルタイムでの推論を実現。MLLMは不確実なサンプルのみに起動し、効率性と精度の両立を実現。

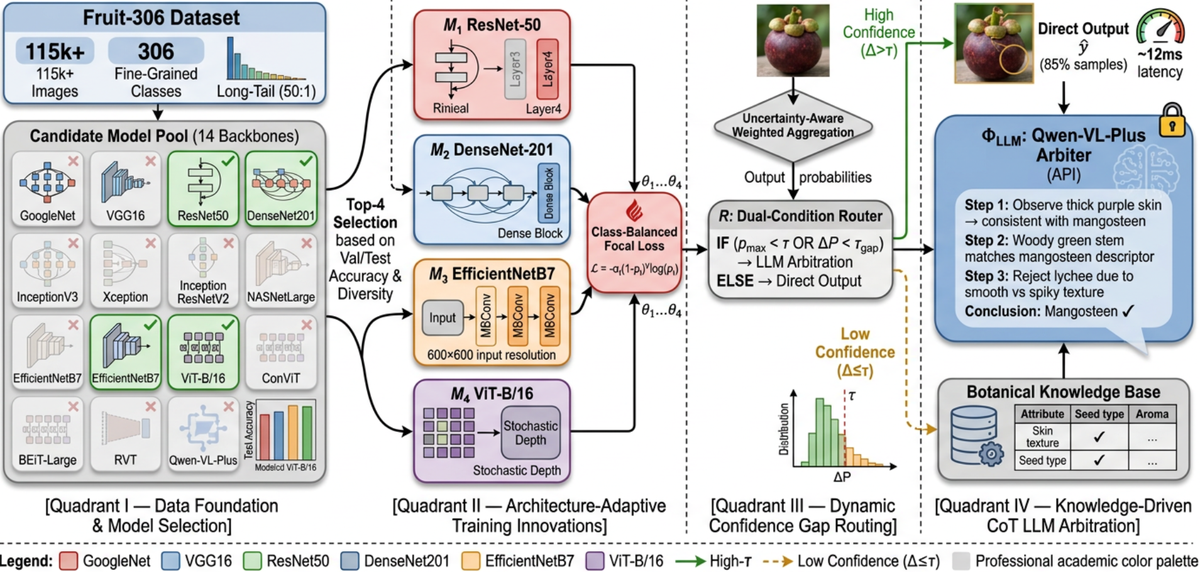
今回の論文は、果物の細粒度分類において、MLLMを用いた動的推論フレームワークを提案するもので、FruitEnsembleと呼ばれます。

なるほど、特に「MLLMを用いた仲裁機構」が印象的ですね。これはどういう仕組みなんでしょうか?
このフレームワークでは、まず複数のモデルを組み合わせたアンサンブルで予測を行い、信頼度が低いサンプルに対してだけ、マルチモーダル大規模言語モデルを呼び出す仕組みです。
あ、つまり、計算リソースを節約できるんでしょうか。
はい、その通りです。特に、信頼度が0.6を下回るサンプルに限ってLLMを起動するように設計されており、効率的な推論が可能になっています。
コストと精度のバランス、いいですね。ただ、データセットの規模はどのくらいなんですか?
この論文では、306の果物カテゴリを含む11万6千件のサンプルから構成されたデータセットを構築しています。これは、非常に大規模で、細粒度分類に適した構造です。
えっ、それだけのサンプルあったんですか。それって実際の農業現場ではデータが手に入りにくいんでしょうか。
はい、確かにデータ収集は大変で、特に細粒度分類には限界があります。この研究では、データの質と量のバランスを取るために、複数の視覚モデルを統合するアプローチをとっています。
なるほど。実際の現場で導入するには、コストの回収期間や導入の難しさも気になるところですね。
その通りです。特に、農業現場では補助金や設備投資の影響が大きいので、ROIの見通しが重要です。この手法は、推論の効率化を重視しており、導入のハードルは低めですが、実運用の際には精度とコストのバランスを調整する必要があります。
技術的には面白いですが、規模や地域によって適用性が変わるんでしょうか。
その通りです。特に、地域ごとの果物の種類や栽培方法の違い、設備の状況など、環境に依存する要素があります。この研究では、汎用性を高めるための設計はされていますが、実際の導入には調整が必要です。
それって、補助金前提の導入になるケースが多いんでしょうか。
補助金の影響は大きいですが、導入の判断は主に技術的・経済的な要因に基づくものであり、現実的なROIの見通しが重要です。
背景と課題
果物の細粒度分類は、品質管理や自動選別に不可欠だが、視覚的類似性の高さとデータ不足が課題である。従来手法は、単一モデルでは精度が低く、言語モデルを用いることで精度向上が期待されるが、コストと速度の問題がある。特に、長尾分布のデータセットでは、稀少品種の識別が困難である。
FruitEnsembleの手法
FruitEnsembleは、4つの異なる視覚モデル(ResNet50、DenseNet201、EfficientNetB7、Vision Transformer)を組み合わせた異種ensembleを用い、信頼度に基づく重み付き融合を行う。信頼度が低いサンプルに対してのみ、マルチモーダル大規模言語モデル(MLLM)を起動し、カテゴリ記述を用いたChain-of-Thought推論を行う。これにより、効率的な推論と高精度な識別を実現。

実験結果
FruitEnsembleは、Fruit-306データセットで70.49%の精度を達成し、既存の最先端モデルを上回る性能を示した。MLLMの起動率は15%にとどまり、リアルタイム推論が可能である。ハードサンプルに特化したjoint lossにより、稀少品種の識別精度が向上した。
意義と応用可能性
FruitEnsembleは、農業現場での自動選別や品質管理に応用可能。特に、視覚的類似性が高い果物の分類において、従来の手法では困難な精度を実現できる。MLLMの選択的利用により、コストと精度のバランスを取れるため、大規模農業での導入が期待される。
限界と今後の課題
FruitEnsembleは、言語モデルの説明性や、カテゴリ記述の質に依存するため、記述の標準化や自動生成が今後の課題である。また、より多くの果物カテゴリに拡張する際には、データのバランスと記述の網羅性が重要となる。
日本での適用可能性
日本では、果物の品種多様性が高く、特に品種の細粒度分類が求められる。FruitEnsembleは、品種の混在が問題となる果物選別ラインや、スマート農業プラットフォームへの導入が可能。特に、日本農業の高付加価値化に寄与する可能性がある。
📊 本論文の主な指標
参考論文
本記事は以下のarXiv論文を参考に、日本語に解説したものです。詳細は元論文をご覧ください。
– タイトル: FruitEnsemble: MLLM-Guided Arbitration for Heterogeneous ensemble in Fine-Grained Fruit Recognition – 著者: Enhui Yu, Junhui Li, Ruitong Lu, Jialu Li, Youshan Zhang – 発表日: 2026-05-20 – arXiv ID: 2605.20892v1 – カテゴリ: cs.CV